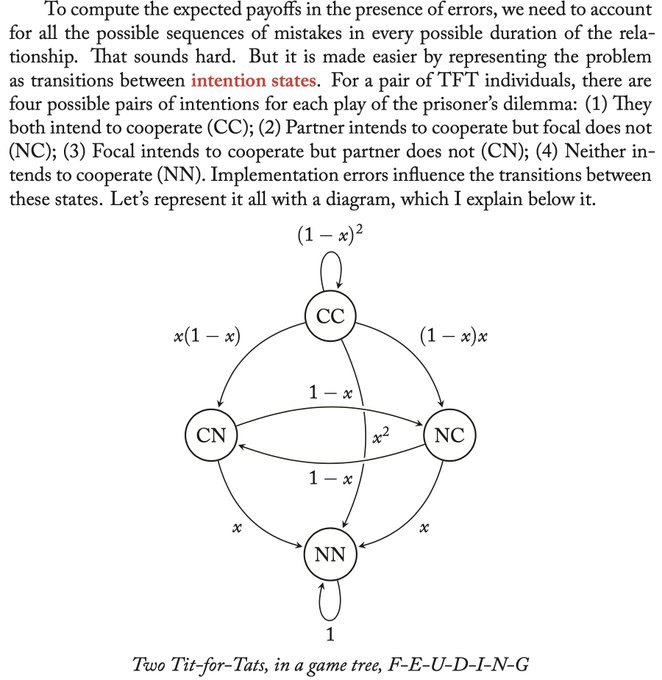
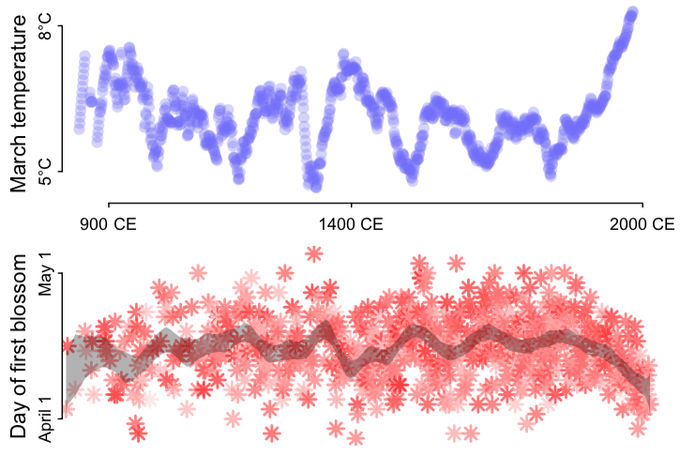
Richard McElreath 🦔
@rlmcelreath
47,811
Followers
2,030
Following
2,707
Media
11,582
Statuses
Anthropologist @MPI_EVA_Leipzig - telling anyone who will listen that, if we are very careful and try very hard, we might not completely mislead ourselves
Don't wanna be here?
Send us removal request.