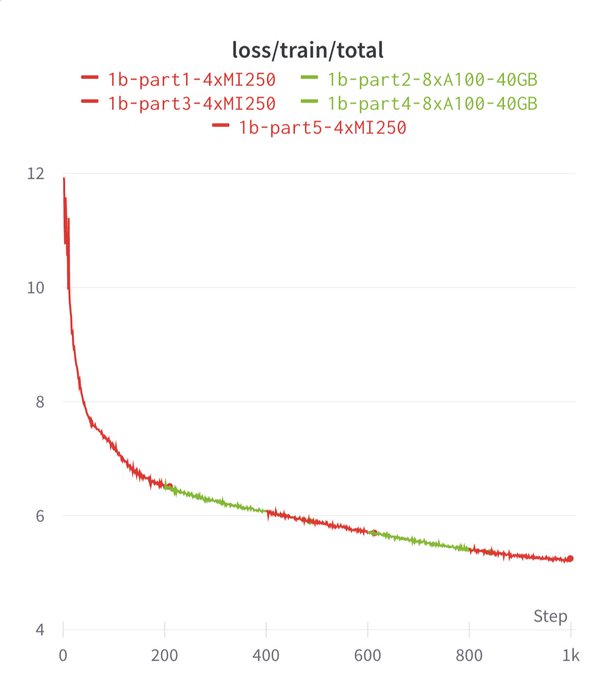
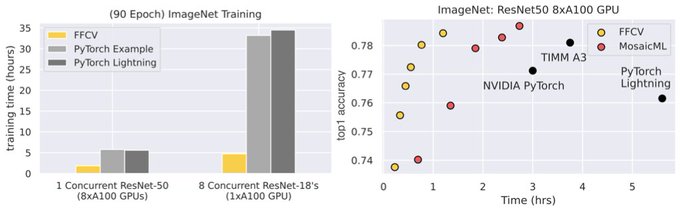
Abhi Venigalla
@ml_hardware
5,600
Followers
1,315
Following
75
Media
913
Statuses
Researcher @Databricks . Former @MosaicML , @CerebrasSystems . Addicted to all things compute.
San Francisco, CA
Joined October 2018
Don't wanna be here?
Send us removal request.