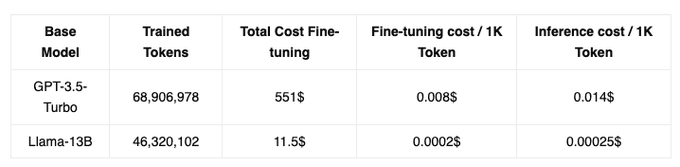
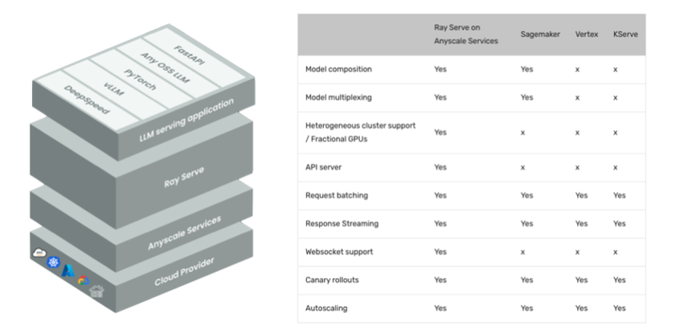
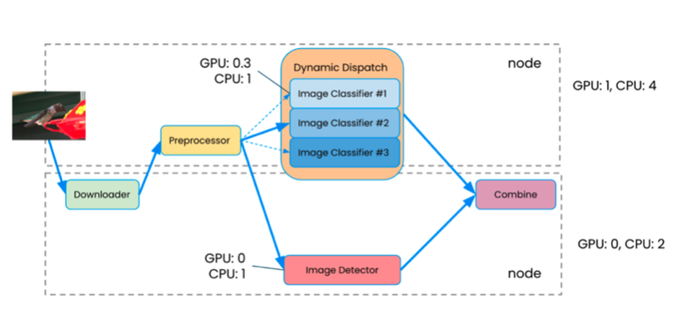
Robert Nishihara
@robertnishihara
6,597
Followers
660
Following
96
Media
1,376
Statuses
Co-founder @anyscalecompute . Co-creator of @raydistributed . Previously PhD ML at Berkeley.
Joined March 2009
Don't wanna be here?
Send us removal request.