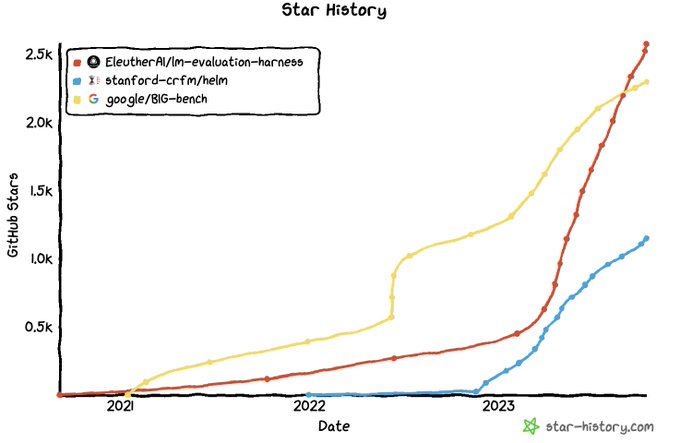
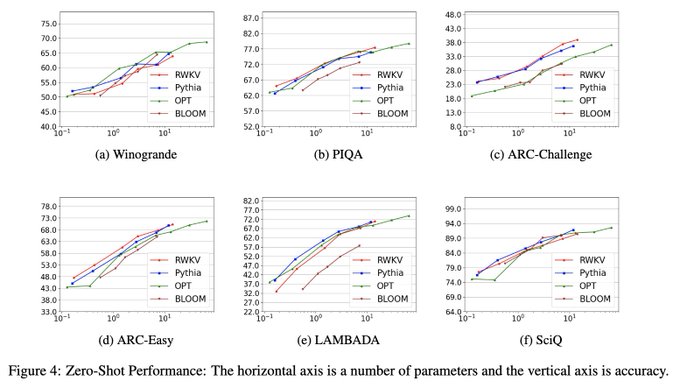
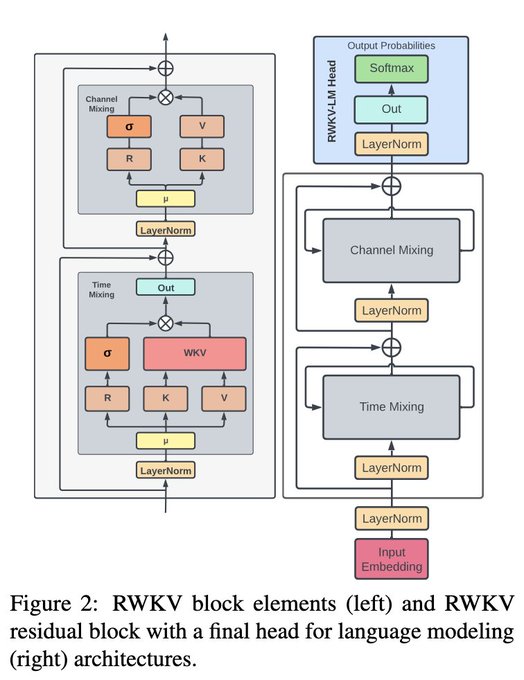
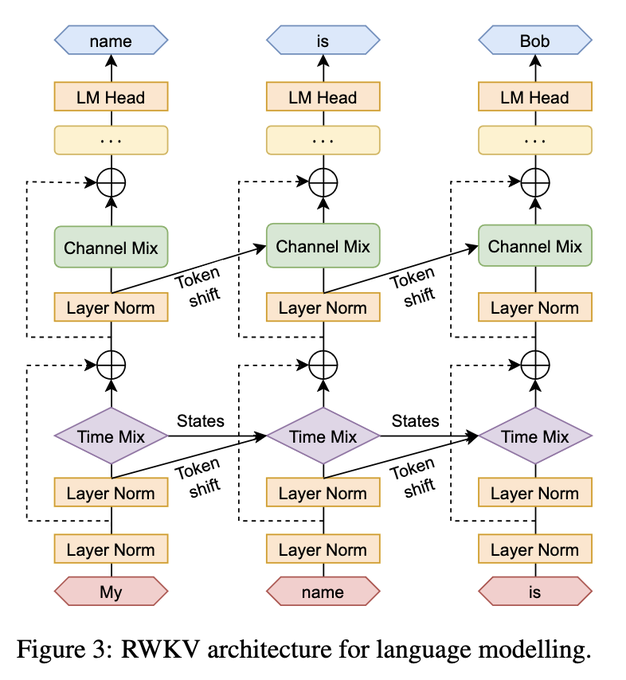
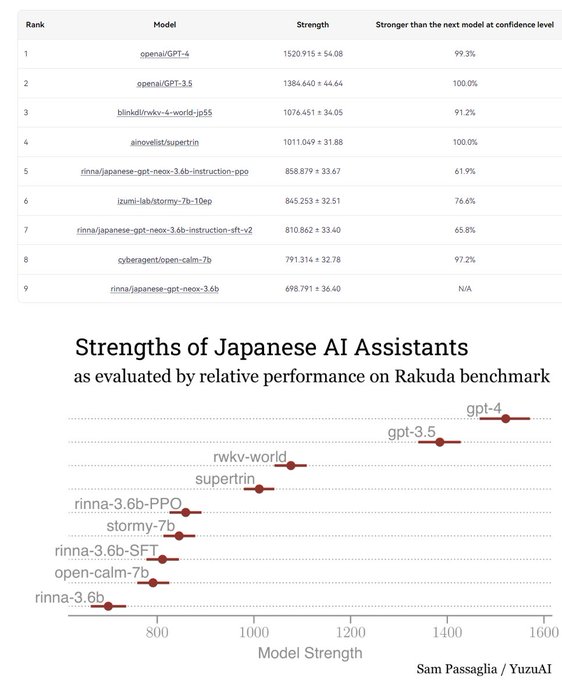
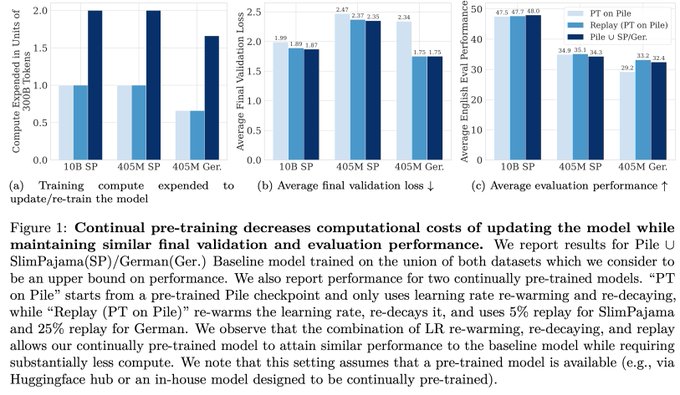
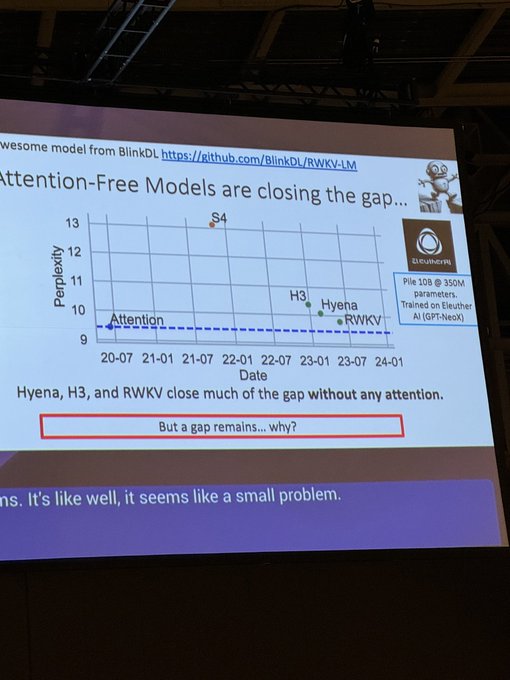
EleutherAI
@AiEleuther
21,152
Followers
78
Following
31
Media
704
Statuses
A non-profit research lab focused on interpretability, alignment, and ethics of artificial intelligence. Creators of GPT-J, GPT-NeoX, Pythia, and VQGAN-CLIP
Joined August 2022
Don't wanna be here?
Send us removal request.