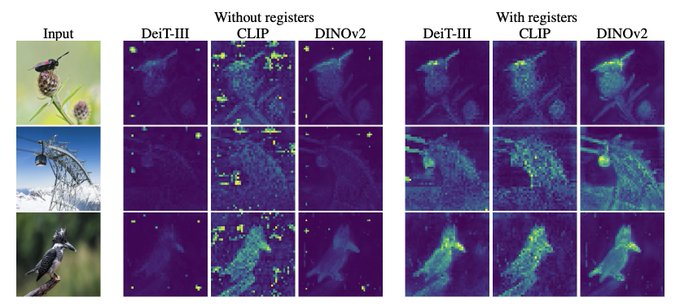
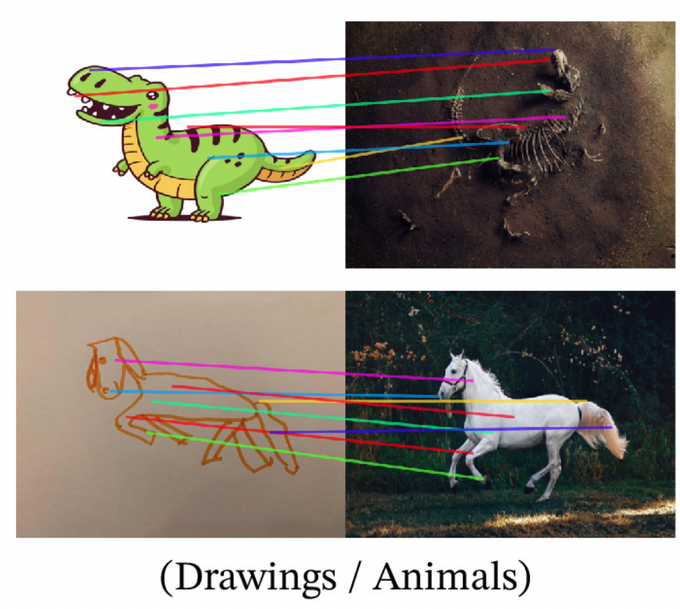
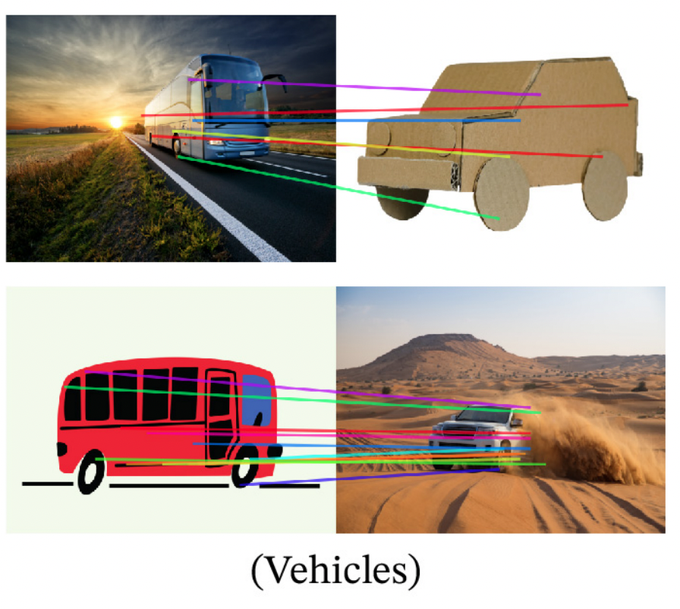
TimDarcet
@TimDarcet
2,755
Followers
618
Following
99
Media
621
Statuses
PhD student, building big vision models @ INRIA & FAIR (Meta)
Joined March 2021
Don't wanna be here?
Send us removal request.