Naman Jain
@StringChaos
1,210
Followers
1,079
Following
23
Media
316
Statuses
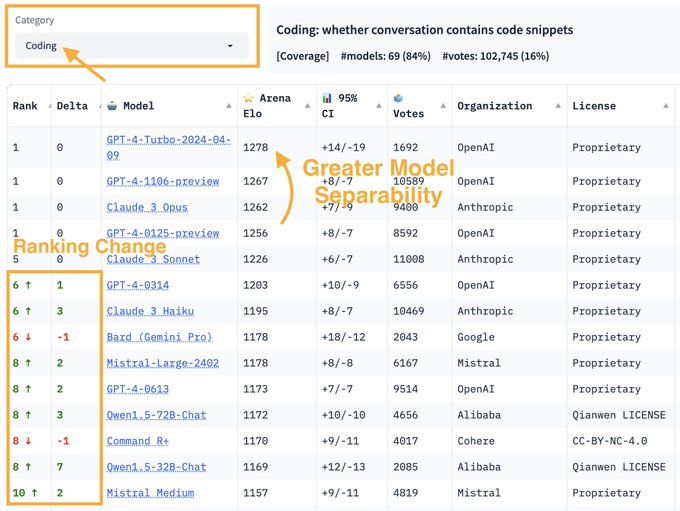
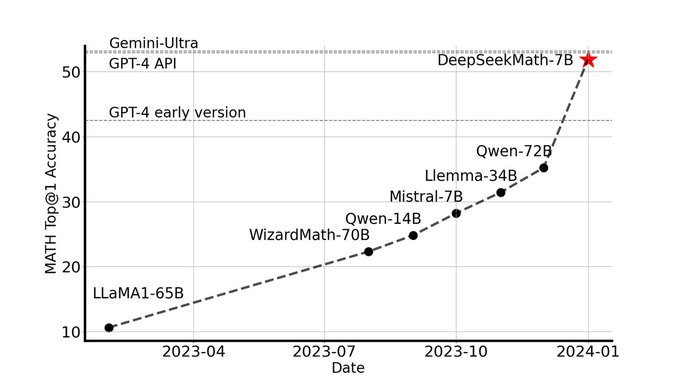
Research Intern @MetaAI | CS PhD @UCBerkeley | Projects - R2E, LiveCodeBench, Chatbot-Arena Coding, RAFT, Code Cleaning | Past: @AWS @MSFTResearch @iitbombay
Don't wanna be here?
Send us removal request.