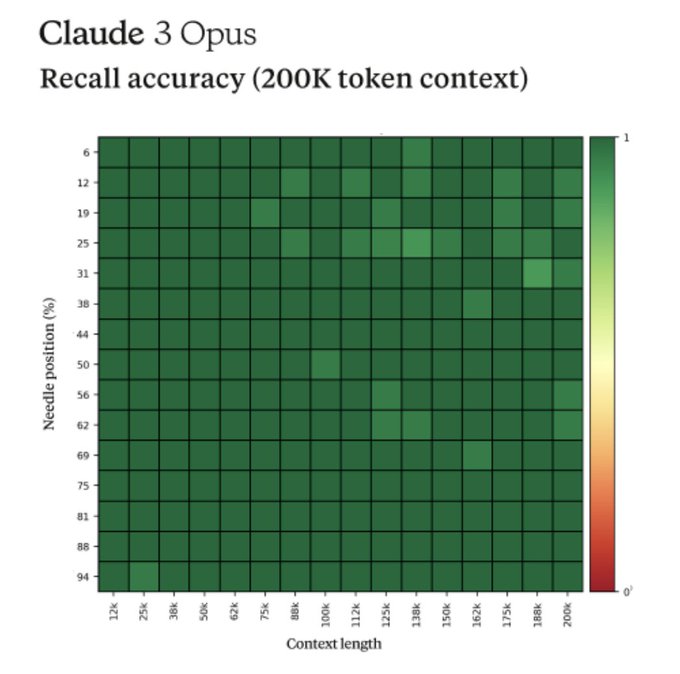
Yanai Elazar
@yanaiela
3,471
Followers
1,203
Following
155
Media
1,791
Statuses
Postdoc @ AI2 & UW | NLP On the academic job market
Don't wanna be here?
Send us removal request.