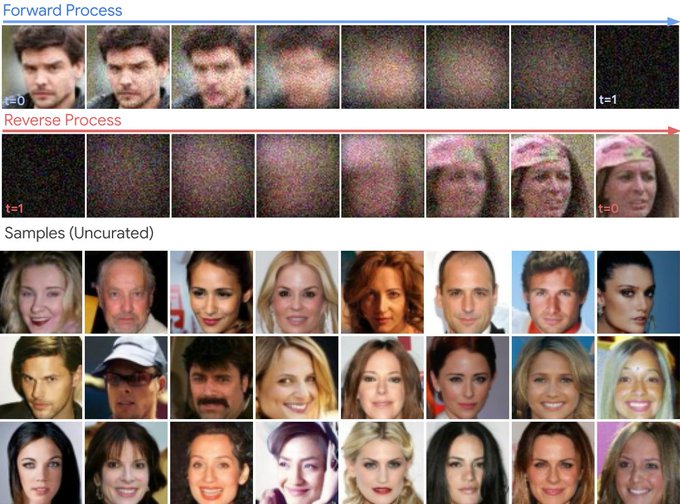
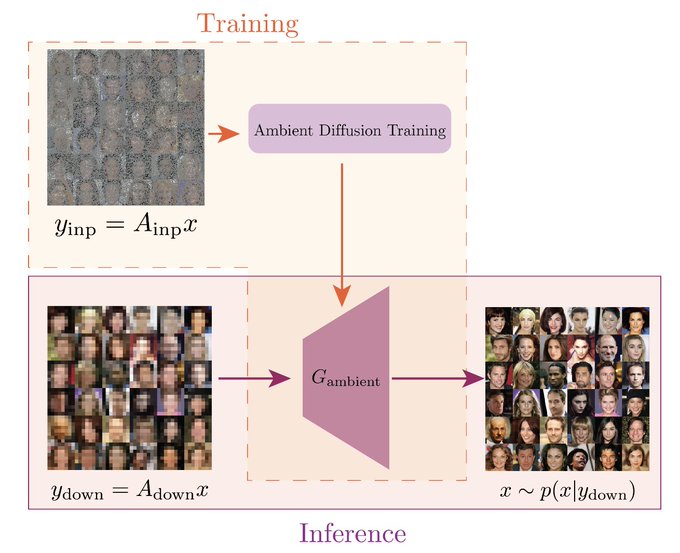
Giannis Daras
@giannis_daras
4,076
Followers
424
Following
134
Media
1,369
Statuses
Ph.D. candidate, Computer Science @UTAustin , working with @AlexGDimakis . Ex: @nvidia , @google , @explosion_ai , @ntua
Joined October 2018
Don't wanna be here?
Send us removal request.