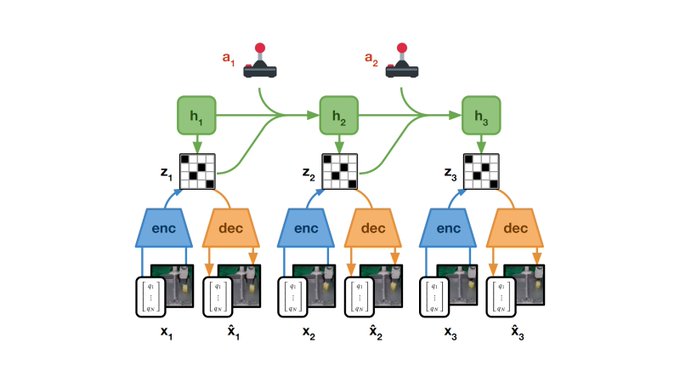
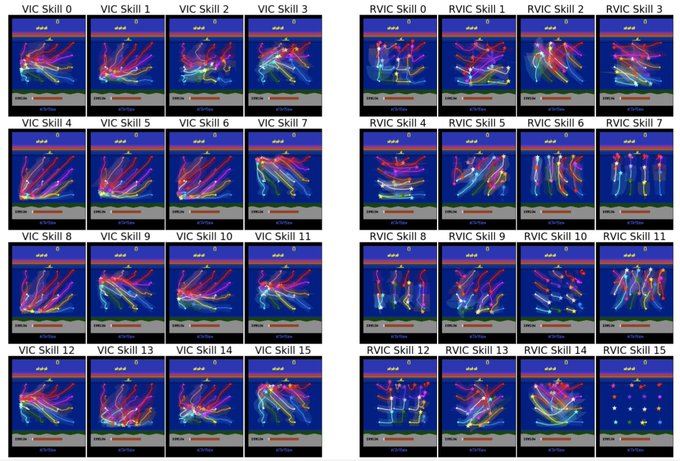
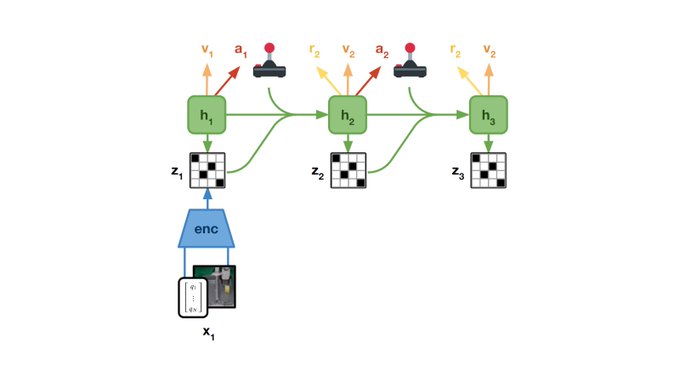
Danijar Hafner
@danijarh
15,782
Followers
909
Following
163
Media
2,385
Statuses
Building AI that makes autonomous decisions using world models, artificial curiosity, and temporal abstraction @DeepMind
Don't wanna be here?
Send us removal request.