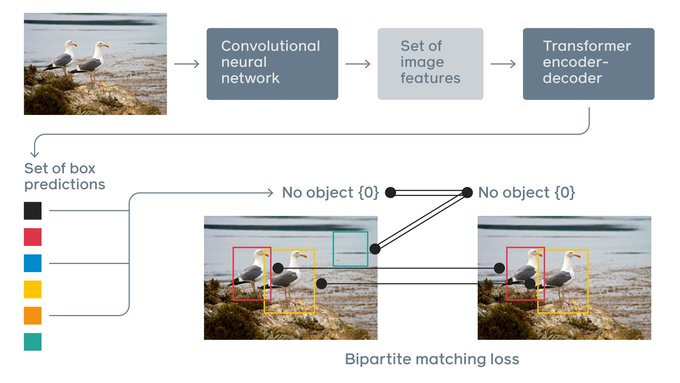
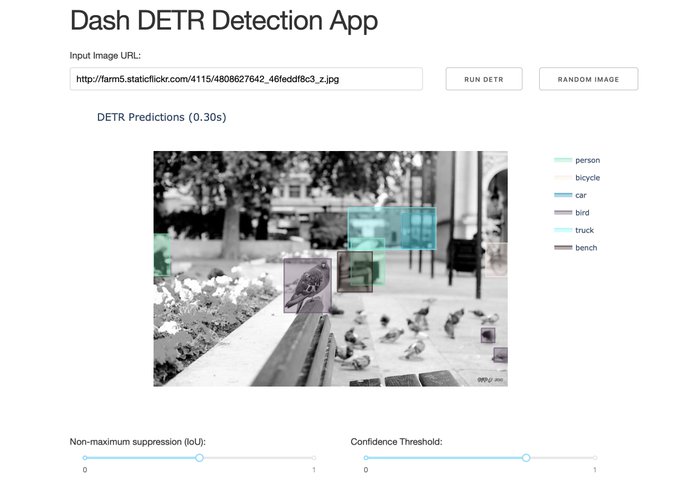
Nicolas Carion
@alcinos26
1,858
Followers
228
Following
11
Media
74
Statuses
Research Scientist at Meta. Previously, post-Doc @nyuniversity , PhD student @FacebookAI Paris. RL, Transformers, Computer Vision.
Don't wanna be here?
Send us removal request.