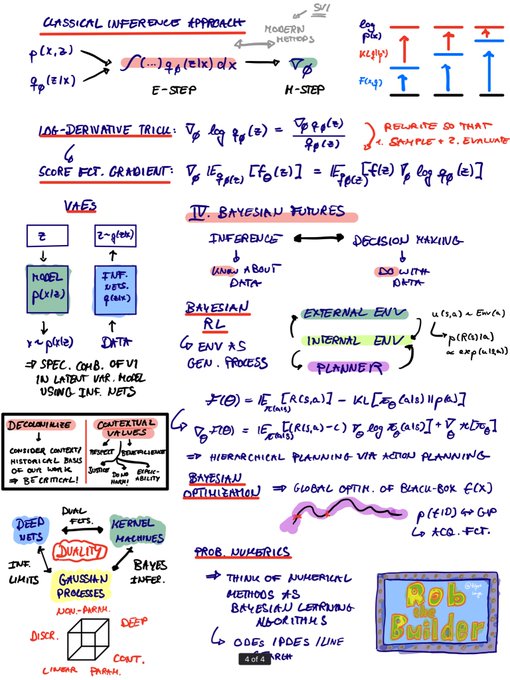
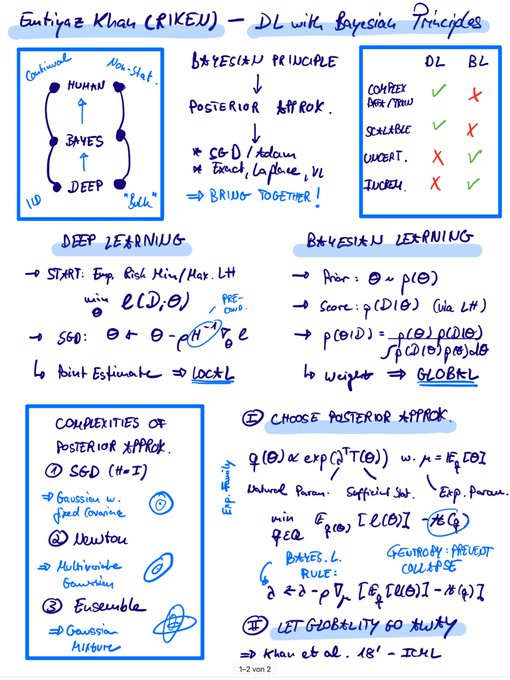
Robert Lange
@RobertTLange
8,206
Followers
558
Following
263
Media
490
Statuses
Founding Research Scientist @SakanaAILabs 🔬AI Scientist 🧬gymnax 🏋️ evosax 🦎 MLE-Infra 🤹 Ex: SR @Google DM. Legacy DeepMind Intern.
Don't wanna be here?
Send us removal request.