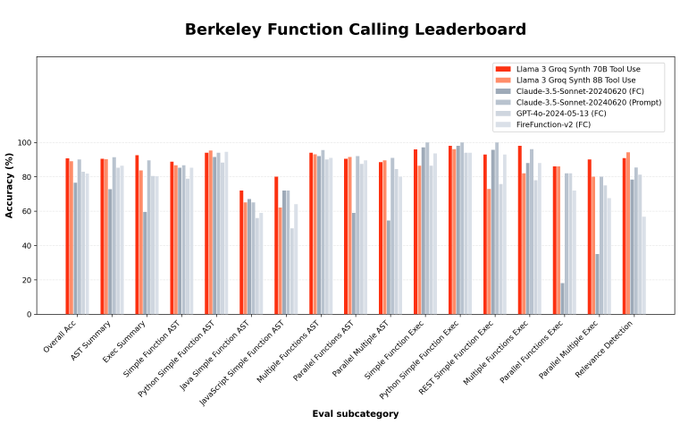
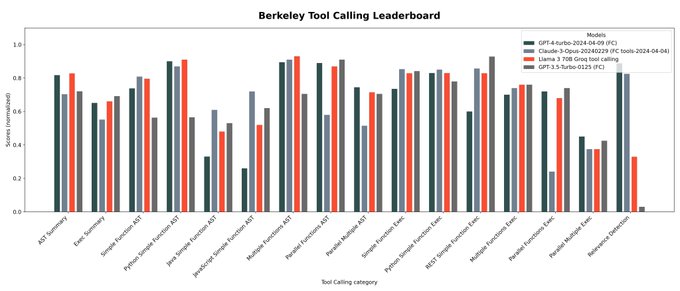
Rick Lamers
@RickLamers
4,300
Followers
813
Following
327
Media
2,112
Statuses
👨💻 AI Research & Engineering @GroqInc . Angel investor. I publish technical resources about LLMs every week. Opinions are my own.
Don't wanna be here?
Send us removal request.