Shunyu Yao
@ShunyuYao12
10,580
Followers
954
Following
79
Media
660
Statuses
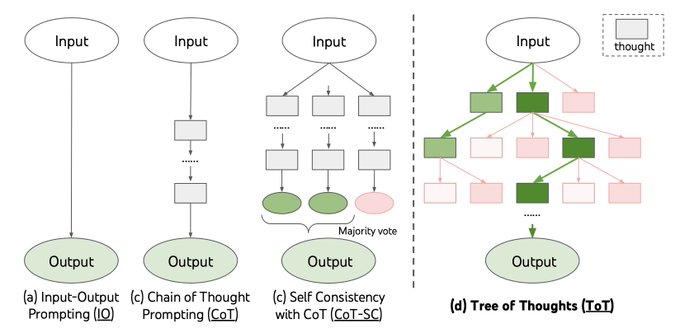
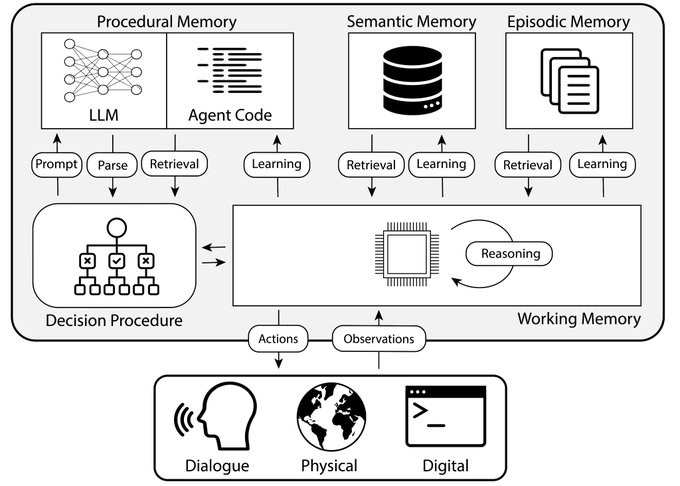
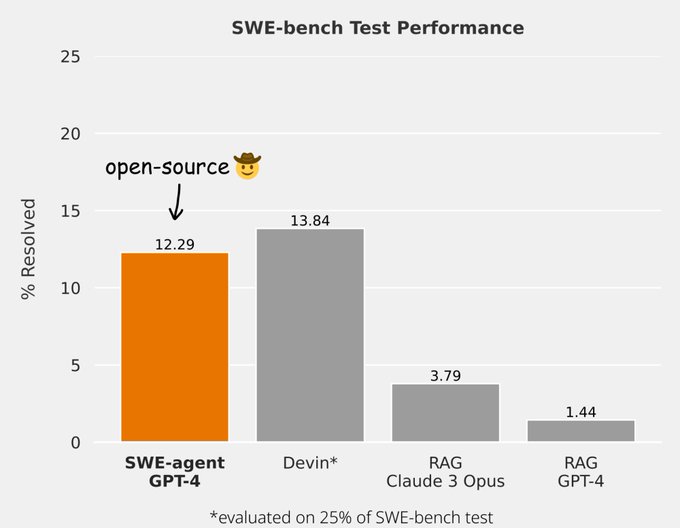
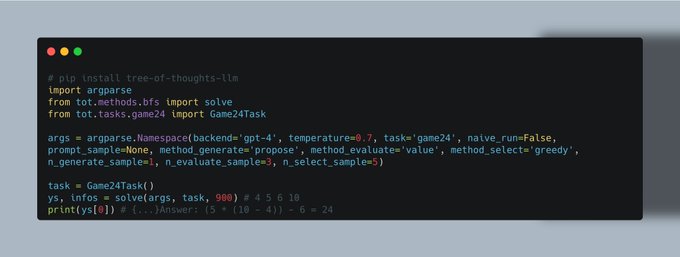
Language agents (ReAct, Reflexion, Tree of Thoughts) for digital automation (WebShop, SWE-bench, SWE-agent)
Joined June 2020
Don't wanna be here?
Send us removal request.